


Introduction
I extracted co-occurence of top 3500 python packages in github repos using the the github data on BigQuery. I implemented the visualization force layout in d3 via the velocity verlet integration. I also clustered the graph using algorithms from python-igraph and updated it to http://graphistry.com/.
See the screenshot of the numpy cluster in the d3 visualization (click image for live version):
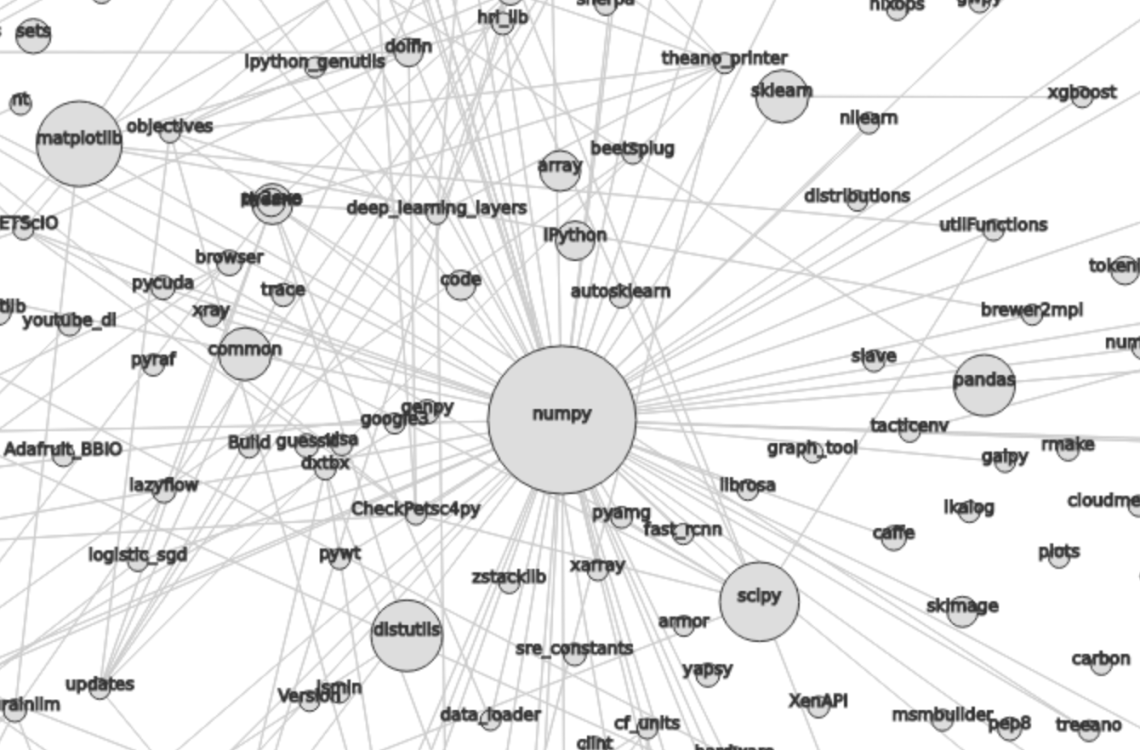
See just the numpy cluster extracted from the graphistry (click image for live version): 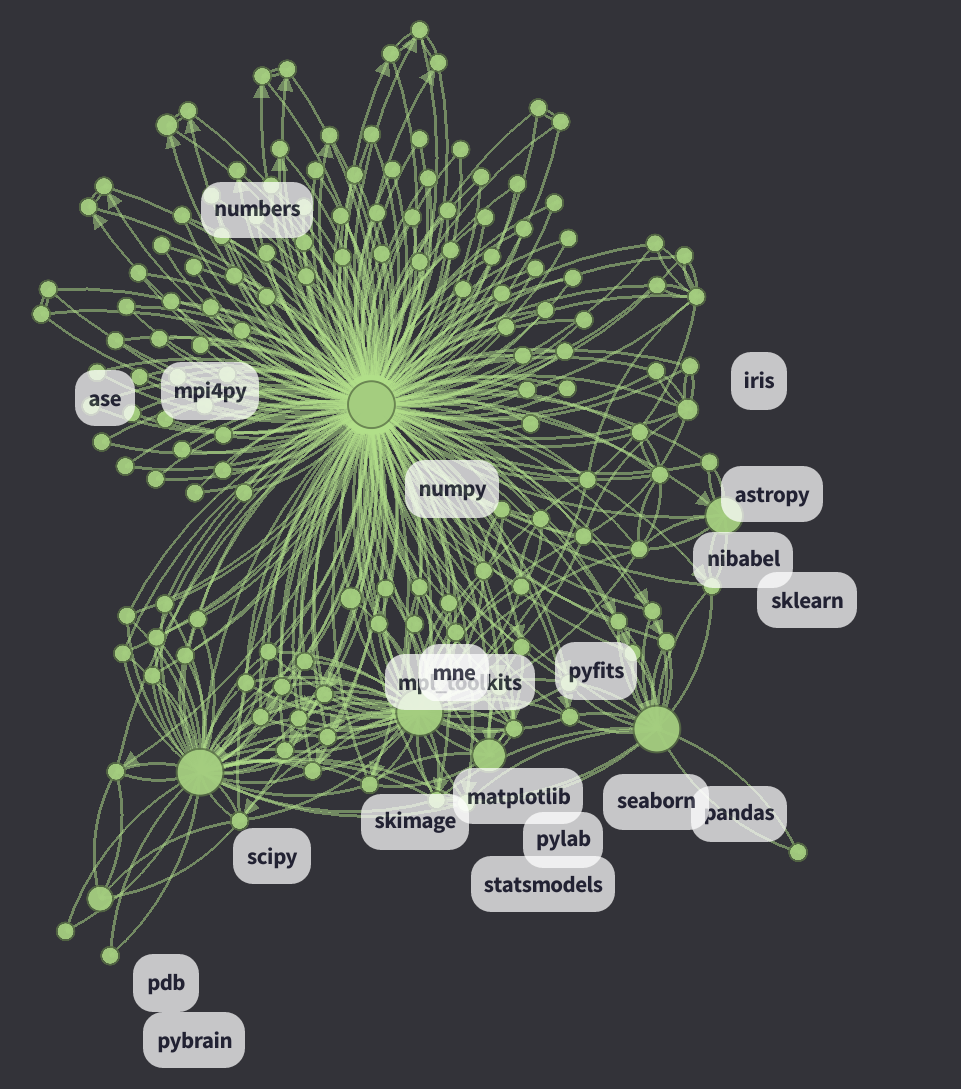
Graph properties:
- Each node is each python package found on github. Radius is calculated in DataFrame with nodes section.
- For two packages A and B, weight of an edge is
, where
is number of occurrences of packages A and B within the same file. I will migrate it to the normalized pointwise mutual information soon, since it is a bit hard to calculate it using the BigQuery.
- Edges with weight smaller than 0.1 are removed.
- The d3 algorithm searches for minimal energy state by the velocity verlet Integration according to simulation parameters.
You can my app at http://clustering.kozikow.com?center=numpy. You can:
- Pass different package names as a query argument in the URL.
- Scroll the page horizontally and vertically.
- Click a node to open the pypi. Note that not all packages are on pypi.
Interesting graphistry views are in the next section, Analysis of specific clusters.
Graph visualizations often lack actionable insights except looking cool. Types of insights you can use this for:
- Find packages you have been not aware of in the close proximity of other packages that you use.
- Evaluate different web development frameworks based on size, adoption and library availability (e.g. Flask vs django).
- Find some interesting python use cases, like robotics cluster.
Analysis of specific clusters
In addition to d3 visualization I also clustered the data using the python-igraph community_infomap().membership and uploaded it to graphistry. Ability to exclude and filter by clusters was very useful.
Scientific computing cluster
Unsurprisingly, it is centered on numpy. It is interesting that it is possible to see the divide between statistics and machine learning.
Web frameworks clusters
Web frameworks are interesting:
d3 links
- It could be said that sqlalchemy is a center of web frameworks land.
- Found nearby, there’s a massive and monolithic cluster for django.
- Smaller nearby clusters for flask and pyramid.
- pylons, lacking a cluster of its own, in between django and sqlalchemy.
- Small cluster for zope, also nearby sqlalchemy
- tornado got swallowed by the big cluster of standard library in the middle, but is still close to other web frameworks.
- Some smaller web frameworks like gluon (web2py) or turbo gears ended up close to django, but barely visible and without clusters of their own.
Interesting graphistry clusters
Other interesting clusters
Looking at results of clustering algorithm, only “medium sized” clusters are interesting. A few first are obvious like clusters dominated by packages like os and sys. Very small clusters are not interesting either. Here you can see clusters between positions 5 and 30 according to size.
Some of the other clusters:
- Testing cluster, d3 link, graphistry cluster
- Openstack cluster, d3 link, graphistry link
- String parsing and formatting cluster
- Robotics land
- gaming cluster
- deep learning cluster
Potentials for further analysis
Other programming languages
Majority of the code is not specific to python. Only the first step, create a table with packages, is specific to python.
I had to do a lot of work on fitting the parameters in Simulation parameters to make the graph look good enough. I suspect that I would have to do similar fitting to each language, as each language graph would have different properties.
I will be working on analyzing Java and Scala next.
Search for “Alternatives to package X”, e.g. seaborn vs bokeh
For example, it would be interesting to cluster together all python data visualization packages.
Intuitively, such packages would be used in similar context, but would be rarely used together. Assuming that our graph is represented as npmi coincidence matrix M, for packages x and y, correlation of vectors x and y would be high, but M[x][y] would be low.
Alternatively, M^2 /. M could have some potential. M^2 would roughly represent “two hops” in the graph, while /. is a pointwise division.
e high correlation of their neighbor weights, but low direct edge.
This would work in many situations, but there are some others it wouldn’t handle well. Example case it wouldn’t handle well:
- sqlalchemy is an alternative to django built-in ORM.
- django ORM is only used in django.
- django ORM is not well usable in other web frameworks like flask.
- other web frameworks make heavy use of flask ORM, but not django built-in ORM.
Therefore, django ORM and sqlalchemy wouldn’t have their neighbor weights correlated. I might got some ORM details wrong, as I don’t do much web dev.
I also plan to experiment with node2vec or squaring the adjacency matrix.
Within repository relationship
Currently, I am only looking at imports within the same file. It could be interesting to look at the same graph built using “within same repository” relationship, or systematically compare the “within same repository” and “within same file” relationships.
Join with pypi
It could be interesting to compare usages on github with pypi downloads. Pypi is also accessible on BigQuery.
Data
- Post-processed JSON data used by d3
- Publicly available BigQuery tables with all the data. See Reproduce section to see how each table was generated.
Steps to reproduce
Extract data from BigQuery
Create a table with packages
Save to wide-silo-135723:github_clustering.packages_in_file_py:
SELECT
id,
NEST(UNIQUE(COALESCE(
REGEXP_EXTRACT(line, r"^from ([a-zA-Z0-9_-]+).*import"),
REGEXP_EXTRACT(line, r"^import ([a-zA-Z0-9_-]+)")))) AS package
FROM (
SELECT
id AS id,
LTRIM(SPLIT(content, "\n")) AS line,
FROM
[fh-bigquery:github_extracts.contents_py]
HAVING
line CONTAINS "import")
GROUP BY id
HAVING LENGTH(package) > 0;
Table will have two fields – id representing the file and repeated field with packages in the single file. Repeated fields are like arrays – the best description of repeated fields I found.
This is the only step that is specific for python.
Verify the packages_in_file_py table
Check that imports have been correctly parsed out from some random file.
SELECT
GROUP_CONCAT(package, ", ") AS packages,
COUNT(package) AS count
FROM [wide-silo-135723:github_clustering.packages_in_file_py]
WHERE id == "009e3877f01393ae7a4e495015c0e73b5aa48ea7"
| packages | count |
|---|---|
| distutils, itertools, numpy, decimal, pandas, csv, warnings, future, IPython, math, locale, sys | 12 |
Filter out not popular packages
SELECT COUNT(DISTINCT(package)) FROM (SELECT package, count(id) AS count FROM [wide-silo-135723:github_clustering.packages_in_file_py] GROUP BY 1) WHERE count > 200;
There are 3501 packages with at least 200 occurrences and it seems like a fine cut off point. Create a filtered table, wide-silo-135723:github_clustering.packages_in_file_top_py:
SELECT
id,
NEST(package) AS package
FROM (SELECT
package,
count(id) AS count,
NEST(id) AS id
FROM [wide-silo-135723:github_clustering.packages_in_file_py]
GROUP BY 1)
WHERE count > 200
GROUP BY id;
Results are in [wide-silo-135723:github_clustering.packages_in_file_top_py].
SELECT
COUNT(DISTINCT(package))
FROM [wide-silo-135723:github_clustering.packages_in_file_top_py];
3501
Generate graph edges
I will generate edges and save it to table wide-silo-135723:github_clustering.packages_in_file_edges_py.
SELECT p1.package AS package1, p2.package AS package2, COUNT(*) AS count FROM (SELECT id, package FROM FLATTEN([wide-silo-135723:github_clustering.packages_in_file_top_py], package)) AS p1 JOIN (SELECT id, package FROM [wide-silo-135723:github_clustering.packages_in_file_top_py]) AS p2 ON (p1.id == p2.id) GROUP BY 1,2 ORDER BY count DESC;
Top 10 edges:
SELECT
package1,
package2,
count AS count
FROM [wide-silo-135723:github_clustering.packages_in_file_edges_py]
WHERE package1 < package2
ORDER BY count DESC
LIMIT 10;
| package1 | package2 | count |
|---|---|---|
| os | sys | 393311 |
| os | re | 156765 |
| os | time | 156320 |
| logging | os | 134478 |
| sys | time | 133396 |
| re | sys | 122375 |
| __future__ | django | 119335 |
| __future__ | os | 109319 |
| os | subprocess | 106862 |
| datetime | django | 94111 |
Filter out irrelevant edges
Quantiles of the edge weight:
SELECT
GROUP_CONCAT(STRING(QUANTILES(count, 11)), ", ")
FROM [wide-silo-135723:github_clustering.packages_in_file_edges_py];
1, 1, 1, 2, 3, 4, 7, 12, 24, 70, 1005020
In my first implementation I filtered edges out based on the total count. It was not a good approach, as a small relationship between two big packages was more likely to stay than strong relationship between too small packages.
Create wide-silo-135723:github_clustering.packages_in_file_nodes_py:
SELECT package AS package, COUNT(id) AS count FROM [github_clustering.packages_in_file_top_py] GROUP BY 1;
| package | count |
|---|---|
| os | 1005020 |
| sys | 784379 |
| django | 618941 |
| __future__ | 445335 |
| time | 359073 |
| re | 349309 |
Create the table packages_in_file_edges_top_py:
SELECT
edges.package1 AS package1,
edges.package2 AS package2,
# WordPress gets confused by less than sign after nodes1.count
edges.count / IF(nodes1.count nodes2.count,
nodes1.count,
nodes2.count) AS strength,
edges.count AS count
FROM [wide-silo-135723:github_clustering.packages_in_file_edges_py] AS edges
JOIN [wide-silo-135723:github_clustering.packages_in_file_nodes_py] AS nodes1
ON edges.package1 == nodes1.package
JOIN [wide-silo-135723:github_clustering.packages_in_file_nodes_py] AS nodes2
ON edges.package2 == nodes2.package
HAVING strength > 0.33
AND package1 <= package2;
Process data with Pandas to json
Load csv and verify edges with pandas
import pandas as pd
import math
df = pd.read_csv(“edges.csv”)
pd_df = df[( df.package1 == “pandas” ) | ( df.package2 == “pandas” )]
pd_df.loc[pd_df.package1 == “pandas”,”other_package”] = pd_df[pd_df.package1 == “pandas”].package2
pd_df.loc[pd_df.package2 == “pandas”,”other_package”] = pd_df[pd_df.package2 == “pandas”].package1
df_to_org(pd_df.loc[:,[“other_package”, “count”]])
print “\n”, len(pd_df), “total edges with pandas”
| other_package | count |
|---|---|
| pandas | 33846 |
| numpy | 21813 |
| statsmodels | 1355 |
| seaborn | 1164 |
| zipline | 684 |
| 11 more rows |
16 total edges with pandas
DataFrame with nodes
nodes_df = df[df.package1 == df.package2].reset_index().loc[:, [“package1”, “count”]].copy()
nodes_df[“label”] = nodes_df.package1
nodes_df[“id”] = nodes_df.index
nodes_df[“r”] = (nodes_df[“count”] / nodes_df[“count”].min()).apply(math.sqrt) + 5
nodes_df[“count”].apply(lambda s: str(s) + ” total usages\n”)
df_to_org(nodes_df)
| package1 | count | label | id | r |
|---|---|---|---|---|
| os | 1005020 | os | 0 | 75.711381704 |
| sys | 784379 | sys | 1 | 67.4690570169 |
| django | 618941 | django | 2 | 60.4915169887 |
| __future__ | 445335 | __future__ | 3 | 52.0701286903 |
| time | 359073 | time | 4 | 47.2662138808 |
| 3460 more rows |
Create map of node name -> id
id_map = nodes_df.reset_index().set_index(“package1”).to_dict()[“index”]
print pd.Series(id_map).sort_values()[:5]
os 0 sys 1 django 2 __future__ 3 time 4 dtype: int64
Create edges data frame
edges_df = df.copy()
edges_df[“source”] = edges_df.package1.apply(lambda p: id_map[p])
edges_df[“target”] = edges_df.package2.apply(lambda p: id_map[p])
edges_df = edges_df.merge(nodes_df[[“id”, “count”]], left_on=”source”, right_on=”id”, how=”left”)
edges_df = edges_df.merge(nodes_df[[“id”, “count”]], left_on=”target”, right_on=”id”, how=”left”)
df_to_org(edges_df)
print “\ndf and edges_df should be the same length: “, len(df), len(edges_df)
| package1 | package2 | strength | count_x | source | target | id_x | count_y | id_y | count |
|---|---|---|---|---|---|---|---|---|---|
| os | os | 1.0 | 1005020 | 0 | 0 | 0 | 1005020 | 0 | 1005020 |
| sys | sys | 1.0 | 784379 | 1 | 1 | 1 | 784379 | 1 | 784379 |
| django | django | 1.0 | 618941 | 2 | 2 | 2 | 618941 | 2 | 618941 |
| __future__ | __future__ | 1.0 | 445335 | 3 | 3 | 3 | 445335 | 3 | 445335 |
| os | sys | 0.501429793505 | 393311 | 0 | 1 | 0 | 1005020 | 1 | 784379 |
| 11117 more rows |
df and edges_df should be the same length: 11122 11122
Add reversed edge
edges_rev_df = edges_df.copy()
edges_rev_df.loc[:,[“source”, “target”]] = edges_rev_df.loc[:,[“target”, “source”]].values
edges_df = edges_df.append(edges_rev_df)
df_to_org(edges_df)
| package1 | package2 | strength | count_x | source | target | id_x | count_y | id_y | count |
|---|---|---|---|---|---|---|---|---|---|
| os | os | 1.0 | 1005020 | 0 | 0 | 0 | 1005020 | 0 | 1005020 |
| sys | sys | 1.0 | 784379 | 1 | 1 | 1 | 784379 | 1 | 784379 |
| django | django | 1.0 | 618941 | 2 | 2 | 2 | 618941 | 2 | 618941 |
| __future__ | __future__ | 1.0 | 445335 | 3 | 3 | 3 | 445335 | 3 | 445335 |
| os | sys | 0.501429793505 | 393311 | 0 | 1 | 0 | 1005020 | 1 | 784379 |
| 22239 more rows |
Truncate edges DataFrame
edges_df = edges_df[[“source”, “target”, “strength”]]
df_to_org(edges_df)
| source | target | strength |
|---|---|---|
| 0.0 | 0.0 | 1.0 |
| 1.0 | 1.0 | 1.0 |
| 2.0 | 2.0 | 1.0 |
| 3.0 | 3.0 | 1.0 |
| 0.0 | 1.0 | 0.501429793505 |
| 22239 more rows |
After running simulation in the browser, get saved positions
The whole simulation takes a minute to stabilize. I could just download an image, but there are extra features like pressing the node opens pypi.
Download all positions after the simulation from the javascript console:
var positions = nodes.map(function bar (n) { return [n.id, n.x, n.y]; })
JSON.stringify()
Join the positions x and y with edges dataframe, so they will get picked up by the d3.
pos_df = pd.read_json(“fixed-positions.json”)
pos_df.columns = [“id”, “x”, “y”]
nodes_df = nodes_df.merge(pos_df, on=”id”)
Truncate nodes DataFrame
# c will be collision strength. Prevent labels from overlaping.
nodes_df[“c”] = pd.DataFrame([nodes_df.label.str.len() * 1.8, nodes_df.r]).max() + 5
nodes_df = nodes_df[[“id”, “r”, “label”, “c”, “x”, “y”]]
df_to_org(nodes_df)
| id | r | label | c | x | y |
|---|---|---|---|---|---|
| 0 | 75.711381704 | os | 80.711381704 | 158.70817237 | 396.074393369 |
| 1 | 67.4690570169 | sys | 72.4690570169 | 362.371142521 | -292.138913114 |
| 2 | 60.4915169887 | django | 65.4915169887 | 526.471326062 | 1607.83507287 |
| 3 | 52.0701286903 | __future__ | 57.0701286903 | 1354.91212894 | 680.325432179 |
| 4 | 47.2662138808 | time | 52.2662138808 | 419.407448663 | 439.872927665 |
| 3460 more rows |
Save files to json
# Truncate columns
with open(“graph.js”, “w”) as f:
f.write(“var nodes = {}\n\n”.format(nodes_df.to_dict(orient=”records”)))
f.write(“var nodeIds = {}\n”.format(id_map))
f.write(“var links = {}\n\n”.format(edges_df.to_dict(orient=”records”)))
Draw a graph using the new d3 velocity verlet integration algorithm
The physical simulation Simulation uses the new velocity verlet integration force graph in d3 v 4.0. Simulation takes about one minute to stabilize, so for viewing purposes I hard-coded the position of node after running simulation on my machine.
The core component of the simulation is:
var simulation = d3.forceSimulation(nodes)
.force("charge", d3.forceManyBody().strength(-400))
.force("link", d3.forceLink(links).distance(30).strength(function (d) {
return d.strength * d.strength;
}))
.force("collide", d3.forceCollide().radius(function(d) {
return d.c;
}).strength(5))
.force("x", d3.forceX().strength(0.1))
.force("y", d3.forceY().strength(0.1))
.on("tick", ticked);
To re-run the simulation you can:
- Remove fixed positions added in one of pandas processing steps.
- Uncomment the “forces” in the javascript file.
Simulation parameters
I have been tweaking simulation parameters for a while. Very dense “center” of the graph is in conflict with clusters on the edge of the graph.
As you may see in the current graph, nodes in the center sometimes overlap, while distance between nodes on the edge of a graph is big.
I got as much as I could from the collision parameter and increasing it further wasn’t helpful. Potentially I could increase gravity towards the center, but then some of the valuable “clusters” from edges of the graph got lumped into the big “kernel” in the center.
Plotting some big clusters separately worked well to solve this problem.
Other posts
You may be interested in my other posts analyzing github data:
Nice!
You might be also interested to know that PyPI download stats are also available in BigQuery:
https://mail.python.org/pipermail/distutils-sig/2016-May/028…
(project recently unveiled by Donald Stufft)
I also added your article to the compilation, thanks for your prolific series of analysis!
It could be a good idea to join usages on github with usages on pypi. For example, to see which packages are more used in proprietary vs open source context.
I suspect that usages on pypi are more representative, so I could create a visualization with node weight based on pypi, but edge weight based on github.
Superb! Robert.
Thanks for the detailed analysis, and telling about the alternative of current network chart.
I liked how you’ve explained this complex code in a really simple description, which makes it easy to understand.
Cheers.. ,\m/
All the best, for what you seek!
Very interesting article. I created a gist with the python code for easy reference.